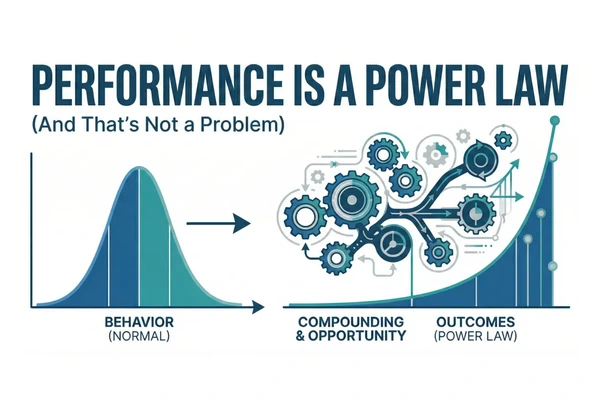
Meta description: Your 9-box grid is probably biased. Learn the 5 bias traps that destroy employee trust, how to spot them in real-time, and why data-driven calibration fixes what subjective ratings break.
The Problem With Your 9-Box Grid
Your leadership team rated 147 people last quarter using a 9-box grid. You got a clean matrix. Problem solved.
Except it wasn't.
Three months later, a high performer you rated as "Core Player" quit. Their manager had rated them "Future Star". They were furious when they found out about the disconnect. Another employee in the "Rough Diamond" box complained to HR that they'd been in the same box for two years despite getting promoted and making budget.
The 9-box grid doesn't fail because the framework is flawed. It fails because of how you implement it.
Subjective opinions, invisible bias, and lack of transparency turn a useful talent assessment tool into a trust-destroying machine.
Here's the thing nobody tells you: the 9-box isn't broken. Your calibration process is. And that's fixable.
What Is the 9-Box Grid (And Why Managers Love It)
The 9-box grid plots employees on two dimensions:
- Vertical axis: Performance (low, medium, high)
- Horizontal axis: Potential (low, medium, high)
This creates nine cells:
| High Potential, Low Performance Rough Diamond | High Potential, Medium Performance Future Star | High Potential, High Performance Star |
| Medium Potential, Low Performance Expert | Medium Potential, Medium Performance Core Player | Medium Potential, High Performance High Performer |
| Low Potential, Low Performance Underperformer | Low Potential, Medium Performance Solid Contributor | Low Potential, High Performance Inconsistent Performer |
Why do leaders love it? Three reasons:
It separates performance from potential. You can be a high performer today but limited in growth (Inconsistent Performer). Or young talent with huge potential but current performance gaps (Rough Diamond). This matters because the development path is completely different.
It enables targeted succession planning. You can immediately see where your bench is weak. No Stars? You have a leadership pipeline problem. Lots of Solid Contributors but no Rough Diamonds? You're stuck in the middle.
It's simple enough to execute. You don't need fancy software. A spreadsheet and some calibration sessions work.
The problem is that simplicity comes at a cost: it relies entirely on manager opinions about both current performance and future potential. And opinions are where bias lives.
Why the 9-Box Destroys Trust (And You Probably Haven't Noticed)
Here's what happens when you implement a 9-box without safeguards:
Employees find out they've been categorized without context. Someone tells them they're in the "Inconsistent Performer" box, or they see an org chart with their box labeled next to their name. Suddenly they're not just evaluated. They're labeled.
The evaluation feels subjective because it is. One manager puts someone in "Core Player" (medium potential, medium performance). Another sees the same person and rates them "Future Star" (high potential, medium performance). They're looking at the same work and reaching different conclusions. The employee notices the inconsistency and assumes politics or bias, not disagreement about potential.
"Potential" is invisible. Performance is measurable. Did you hit your revenue target? Did you deliver the project on time? Potential is murky. How do you know if someone has "high potential"? Is it based on certifications they have? Conversations they've had? How much their manager likes them? Employees don't know what signal you're using, so they assume it's subjective (and usually, it is).
Transparency creates resentment. If you tell an employee they're in a "Rough Diamond" box, you're saying "we don't think you're performing now, but we believe in you." That sounds positive, except it often means: "We're not paying you like a high performer, not promoting you yet, but we're watching." Cue the trust erosion.
Lack of transparency creates paranoia. If you don't tell employees where they fit, they fill the gap with imagination. "Am I a Star? A Future Star? Are they planning to lay me off?" The absence of information breeds anxiety, which breeds distrust.
The same person can be in different boxes depending on who's rating them. Your marketing manager sees your designer as a "Star" (high performance, high potential). Engineering sees them as a "Solid Contributor" (medium performance, medium potential). These conflicting signals make the evaluation feel arbitrary.
Add all this up and the 9-box doesn't feel like a thoughtful talent assessment tool. It feels like an opaque, biased process where decisions happen behind closed doors.
⚠️ The Trust Test: Ask five of your employees what they think their 9-box rating is. If their guesses don't match their actual ratings, your calibration process is not transparent enough. If they feel blindsided by their rating, you have a trust problem.
The 5 Bias Traps That Tank Your 9-Box Implementation
This is where most organizations go wrong. These aren't theoretical problems. These are what actually happens in your calibration sessions.
1. Recency Bias. You Rate the Last Three Months, Not the Year
Your product manager shipped two bad releases in November. It's January, and they're still in your head. When you rate them, you're thinking of those failures, not their three strong quarters before that.
Result: Someone who performed well most of the year gets rated "Core Player" instead of "High Performer" because their recent failure weighted too heavily.
Fix: Bring actual performance data to the calibration session. Not opinions about recent events. Data.
2. The Halo/Horn Effect. One Strong Trait Distorts Everything
Your VP of Sales is brilliant at presentations. He closes deals. But he's disorganized and his team has high turnover. You know this intellectually. When you rate him, the "great closer" image dominates, and you rate him as a "Star" even though his team is a mess.
Result: Someone gets rated on one visible strength, not their full contribution.
Fix: Define performance metrics before the calibration session. Don't just assess "performance." Assess specific behaviors: revenue, team retention, process adherence, etc.
3. Potential Rating is Purely Subjective. Nobody Actually Knows Who's Got It
You're in a calibration meeting. Someone says, "I think Sarah has high potential." Why? "She's smart and motivated." But so is half your team. What specifically shows high potential for a future leader role? Is it:
- Previous promotions or expanded scope?
- Completion of leadership training?
- Feedback from multiple managers who've seen her in different roles?
- Stretch projects where she succeeded?
If you don't have an answer, you're guessing. And when you guess, bias fills the gaps. Tall people are perceived as having higher potential. People who socialize with leaders are seen as more capable. People from the same background as the raters are rated higher.
Result: Potential becomes a proxy for "I like this person" or "This person reminds me of successful people I know."
Fix: Define potential based on observable behaviors and outcomes, not gut feel. "High potential for future leadership" should mean: previous promotion success, 360 feedback showing leadership signals, recent stretch assignment performance.
4. Anchor Bias. Last Year's Rating Sticks
You rated someone as "Core Player" last year. It's the calibration meeting. You see "Core Player" in the spreadsheet and don't really re-evaluate. They stay a "Core Player" because moving them feels like admitting you were wrong last year.
Or they're rated in the first batch of the session, their box becomes the "anchor" in your mind, and similar people all gravitate toward that same box.
Result: People stay in the same box even when their performance changes.
Fix: Start each calibration from scratch. Don't show last year's ratings until after the new rating is complete.
5. Similarity Bias. You Rate People Like You as Higher Potential
You were promoted to VP because you were a strong IC (individual contributor) who moved into management. When you see a strong IC in your team, you see yourself and you overestimate their potential for management. You rate them as a "Future Star" because you imagine them following your path.
But they might not want to manage. And they might not be good at it. You rated them high potential based on similarity to you, not on actual leadership signals.
Result: High performers get pushed toward roles they're not suited for. Lower performers from different backgrounds get stuck in "Solid Contributor" boxes even though they have leadership potential.
Fix: Bring diverse raters to the calibration table. If the leadership team is 8 white men, they'll rate white men as higher potential. That's not a coincidence.
How to Use the 9-Box Without Destroying Trust: A Framework
Here's how to do this right:
Step 1: Define Performance Metrics Upfront (Before Calibration)
"Performance" can't be vague. Define it by role or function:
For sales:
- Revenue closed
- Close rate
- Pipeline health
- Customer retention
For product:
- Features shipped
- Quality metrics (bugs per feature)
- Stakeholder satisfaction
- Timeline accuracy
For people/operations:
- Hiring metrics
- Cost per hire
- Time to productivity
- Employee engagement scores
Get these numbers in the room before the calibration session. Don't rate performance on "gut feel." Rate it on actual metrics.
Step 2: Define Potential on Observable Behaviors (Not Intuition)
"High potential for leadership" should be operationalized:
✓ Successfully led a cross-functional project
✓ Received "leadership" feedback from 360 review (≥80% scores on leadership questions)
✓ Mentored at least one junior employee who was promoted
✓ Volunteered for stretch projects outside their core role
"High potential for deep expertise" (Expert category):
✓ Certified in their domain
✓ Recognized by peers as a go-to expert
✓ Took on mentorship responsibilities
✓ Knowledge they hold is hard to replace
Use THESE criteria, not "I think they have potential."
Step 3: Bring Diverse Raters (Not Just Their Manager)
One person's opinion is bias waiting to happen. Assemble raters who see the person in different contexts:
- Their direct manager (sees day-to-day work)
- Cross-functional peers (see them in collaboration)
- Direct reports or project leads (see them in different roles)
- Skip-level manager (sees them without filter)
Compare ratings. If one rater puts someone as a "Star" and another puts them as "Core Player," that's valuable data. It suggests you need to dig deeper, not average the ratings and move on.
Step 4: Make the Calibration Process Transparent and Documented
During the session:
- Have someone record the discussion (not just the outcome)
- Document WHY someone was rated in a particular box
- Capture the specific performance data and potential signals used
- Note any disagreements between raters
Why? Because when an employee asks "Why am I in the Rough Diamond box?", you have an actual answer: "Your performance metrics show [X], but your 360 feedback and project work show these leadership signals: [Y]. You have high potential but need to close the current performance gap."
Step 5: Communicate Results With Context
This is where most organizations fail. They communicate the box, not the reasoning.
❌ Bad: "You're rated as a Solid Contributor."
✓ Good: "Your performance metrics are strong. You consistently hit targets and deliver quality work. That's why you're rated as a Solid Contributor. Your 360 feedback doesn't show the stretch project leadership we look for in Future Star ratings, so we've flagged you for a cross-functional project next quarter to get you there. Here's what we're looking for: [specific behaviors]."
Context replaces suspicion with understanding. Transparency replaces rumors with clarity.
💡 Key Insight: The difference between a trust-building 9-box implementation and a trust-destroying one isn't the framework. It's whether employees understand the reasoning behind their rating.
Why Data-Driven Calibration Actually Works
Here's where tools like Confirm come in.
Manual calibration is subject to all five bias traps above. You bring subjective opinions to the table, you rely on gut feel about potential, you unconsciously favor people similar to you.
Data-driven calibration flips the script:
Instead of: "I think Marcus has high potential."
You get: "Marcus has been promoted twice, scored 89% on leadership competencies in his 360, led the three highest-impact projects last year, and his skip-level manager independently rated him as a high performer. His performance vs. potential comparison shows room to grow, but the signals are clear."
Instead of: "We should keep Sarah in Core Player because she's solid."
You get: "Sarah's metrics are in the 78th percentile for her function. Her manager rates her high performer. Her peers rate her differently. 5 people rated her high, 3 rated her medium. Let's investigate the gap before rating her."
Instead of: "I don't see leadership potential in this person."
You get: "This person hasn't had a stretch assignment yet. Their performance on technical metrics is strong, but we don't have data on leadership capability. Recommend: assign to cross-functional project, re-evaluate after 6 months."
Data-driven calibration doesn't eliminate bias. Nothing does. But it makes bias visible, prevents single-person opinions from dominating, and creates a defensible reasoning trail when you need to explain decisions.
Step-by-Step: Running Your First Data-Driven 9-Box Calibration
Here's the actual process:
Phase 1: Prep (2 weeks before calibration)
Define performance metrics for each function. Sales, engineering, product, people ops, etc. What does "high," "medium," and "low" performance actually mean?
Gather the data. Pull metrics from your HRIS, CRM, project management tools. Revenue, customer satisfaction, project velocity, quality scores, engagement survey results. Get 6-12 months of data.
Assemble raters. Identify who will be in the calibration room. For each person being rated, aim for 3-4 raters who see them in different contexts.
Define potential criteria. In writing. "High potential for leadership" = [specific, observable behaviors]. "High potential for deep technical expertise" = [specific behaviors]. Write it down.
Phase 2: The Calibration Session (4-6 hours for 30-50 people)
Review performance metrics first. No subjective talk yet. "Here's what the data shows about each person's performance." Sort people into High/Medium/Low performance based on actual metrics. This is not subjective.
Now discuss potential, with data. "High potential candidates are people who've shown these signals: [specific behaviors]." Review which people fit these criteria based on documented evidence (past promotions, 360 feedback, stretch project results). Disagree? Document the disagreement and the reason.
Plot on the 9-box. The matrix fills itself. High performance + high potential = Star. Medium performance + high potential = Future Star, etc.
Identify gaps and outliers. "This person is a Star but has been here 5 years without promotion. We have a retention risk." Or, "This is a Future Star but their manager's rating is 1 point different from their peers. Let's understand why."
Plan actions. For each box: What's our strategy? Stars get promoted, developed, paid competitively. Rough Diamonds get coaching, mentorship, stretch assignments. Underperformers get a performance plan or transition. Document the plan.
Phase 3: Communication (1-2 weeks after calibration)
Brief managers. "Here's how your people were rated and why." Give them the data-based reasoning so they can answer employee questions.
Communicate with employees. In a 1-on-1, discuss the rating with context. Why? Not "you're a Rough Diamond" but "your performance metrics show [X], but your potential is clear based on [Y], and here's what success looks like: [Z]."
Create development plans. "If you want to move from Future Star to Star, here are the performance gaps to close." Give them a path.
The 9-Box Grid Comparison: How It Stacks Up Against Alternatives
You might be wondering: is the 9-box still the best option? Or are there better frameworks?
| Framework | Strengths | Weaknesses |
|---|---|---|
| 9-Box Grid | Simple. Separates performance from potential. Good for succession planning. | Subjective. Relies on accurate potential assessment (hard). Requires careful implementation to avoid bias. |
| 4-Box Grid | Simpler than 9-box. Still separates performance and potential. | Less granular. Harder to differentiate within medium performance/potential. |
| Forced Ranking | Forces clarity. You must choose. | Damages morale. Assumes zero-sum competition. Destroys trust worst of all frameworks. |
| Skills Matrix | Based on current capabilities, not subjective potential. | Doesn't predict future performance. Hard to maintain at scale. |
| Organizational Network Analysis | Data-driven. Shows actual influence and collaboration patterns. | Complex to implement. Hard to explain to managers. Requires special tools. |
The bottom line: The 9-box grid is still the most practical framework for mid-to-large organizations. But only if you do it right—with data, diverse raters, and transparency. If you're doing it based on gut feel and single raters, abandon it and use something else.
FAQ: Your 9-Box Implementation Questions Answered
How often should we re-rate people on the 9-box?
Once a year, minimum. Quarterly if you're in a fast-growing organization. Performance changes. People get promoted, take on new roles, develop new skills. Annual calibrations let your talent picture go stale fast. Quarterly refreshes are better if you have the bandwidth. But at minimum, annual.
What if a person is in a different box depending on who's rating them?
That's not a bug; it's data. If manager A rates someone as "High Performer" and manager B rates them as "Core Player," you have a disagreement about their actual performance. This usually means:
- They perform differently in different contexts (strong with manager A's team, less strong with B's)
- The raters have different standards for "high performance"
- One rater is closer to their work and has better data
Bring the raters together and resolve it. Don't average the ratings and pretend there's agreement. The disagreement itself is useful.
Should we tell employees their 9-box rating?
Yes, with context. Transparency is the only way to preserve trust. Telling someone "you're a Rough Diamond" without explanation breeds resentment. Explaining "your performance on [metrics] is in the medium range, but your 360 feedback and project results show high potential, and here's what high performance looks like for your role" is transparent and actionable.
If you can't explain why someone got their rating, your rating isn't defensible.
What if someone disagrees with their rating?
Listen. They might see data you're missing. They might disagree with how you defined performance or potential. They might have a point.
Process: Have the raters review their data. Re-discuss if new information surfaced. Explain the reasoning in detail. If they still disagree, it's okay. Document the disagreement. Move forward. Come back to it next cycle with more data.
Can we use the 9-box for compensation decisions?
Carefully. Don't create a rigid rule: "Stars get 15% raises, Core Players get 8%." This kills trust if compensation doesn't match performance metrics.
Instead, use 9-box ratings as ONE input into compensation decisions. Combine with: market data, individual performance metrics, tenure, skills. The 9-box grid is useful for identifying high performers and future leaders—but never use it as the sole basis for pay.
What if we're a small team? Is the 9-box worth it?
For teams under 15 people, no. The 9-box is designed to reveal patterns across larger groups. In a small team, you already know who the strong performers are. Formal calibration adds overhead without benefit.
For teams 15-50, the 9-box starts making sense. For 50+, it's clearly valuable for succession planning and identifying development opportunities.
How do we handle the "Rough Diamond" conversation? Isn't that demoralizing?
Only if you explain it wrong. Rough Diamond should sound like: "We believe in you. Your current performance is below our standard for your role—here's what we need to see. But your 360 feedback and potential indicators show you can get there. We're going to invest in your development because we see your upside."
If it sounds like "you're not good enough yet," you've failed at communication. The box label matters less than the development path you create.
The Bottom Line: How Confirm Helps You Get This Right
The 9-box grid works when:
✓ You define performance metrics upfront (data, not opinions)
✓ You involve diverse raters who see the person in different roles
✓ You measure potential on observable behaviors, not gut feel
✓ You document the reasoning and make it transparent
✓ You actually use the ratings to inform development and succession planning
Without these elements, the 9-box grid becomes an opaque, subjective process that destroys trust.
Confirm's approach uses data to make each of these steps defensible. You get:
Automatic bias detection. We flag when ratings look suspiciously similar (suggesting anchoring), when single raters dominate (insufficient diverse input), or when performance metrics don't match subjective potential ratings.
Multi-rater calibration. Build in diverse perspectives automatically. See when one manager rates differently than peers and understand why.
Transparent reasoning. Document why each person got their rating. When an employee asks "Why aren't I a Star?", you have a specific, data-backed answer.
Development paths. Link 9-box ratings to clear next steps. "You're a Future Star. Here's the performance gap to close to become a Star."
The 9-box grid didn't destroy your trust. The way you implemented it did. Fix the implementation, and the 9-box becomes one of your most valuable talent tools.
Internal Links:
- 9-Box Performance Review Guide: Full Definitions & Common Mistakes
- Data-Driven Talent Calibration: The Modern Alternative to Subjective Ratings
- Succession Planning Framework for Mid-Market Companies
- 360 Feedback: How to Use It Without Damaging Trust
Next Steps
Ready to transform your 9-box implementation from trust-destroying to trust-building?
The right approach starts with data. If you're currently rating potential based on gut feel and single managers' opinions, you have a bias problem that a spreadsheet can't solve.
Schedule a conversation with our talent leaders to see how organizations are using data-driven calibration to make the 9-box work—without the politics and bias.